Text-to-SQL을 위한 랭체인 Vector DBLess 환경 구축하기(ClovaXEmbeddings 활용)

AI를 활용하여 자연어를 SQL로 변환하는 기술을 Text-to-SQL 또는 NL2SQL이라고 부릅니다. 이 기술을 적용하기 위한 프롬프트로는 일반적으로 테이블 스키마 정보, 쿼리 생성 시 주의사항, 예시 등이 있는데요.
만약, 테이블을 여러 개 갖고 있는 경우 모든 테이블에 대한 스키마 정보를 프롬프트로 담기에는 LLM이 처리할 수 있는 context 길이에 제한이 있기 때문에 이 경우에는 사용자 쿼리로부터 필요한 정보만을 프롬프트로 사용해야 하는 기술이 추가적으로 필요합니다.
이때 사용자 질문을 해석해 의미상 어떤 테이블을 조회하는 것이 가장 적합할지 찾아주는 기능을 Vector database와 임베딩 모델로 해결할 수 있습니다. 그러나 시중의 Vector Database를 도입하기에는 비용이나 인프라측면에서 부담스러울 수도 있는데요.
다행히도, 적재하려는 스키마 정보량이 대용량이 아닌 경우에는 랭체인의 In-memory 방식의 Vector 저장소를 사용할 수 있습니다. DB에 넣지 않고 CPU의 memory를 사용하기 때문에 비용면에서도 부담이 훨씬 덜 할 수 있습니다.
따라서 이번 포스팅에서는 CLOVA Studio에서 서비스 중인 Text-Embedding 모델과 랭체인 프레임워크를 활용해서 Vector DBLess 환경을 구축하는 방법에 대해 한번 알아보도록 하겠습니다.
🤔 임베딩 모델을 사용하는 이유?
CLOVA Studio에서 제공하고 있는 Text-Generation 모델인 하이퍼클로바X (HCX-003, HCX-003-DASH)는 사용 가능한 토큰 수(Context window)가 최대 4096 토큰으로 제한되어 있습니다. 이 말은 시스템 메시지, 사용자 메시지, AI 답변 메시지 모두 통틀어 4096 토큰을 넘길 수가 없다는 뜻인데요, 다시 말씀드려 무거운 프롬프트를 사용한다면 대화를 몇 번 주고받지도 않았는데도 빠르게 제한에 걸릴 수 있게 됩니다.
다만, 앞서 얘기한 Text-to-SQL 같은 기술을 적용하려면 기본적으로 스키마 정보를 프롬프트에 담아야 하기 때문에 시스템 메시지 또는 사용자 메시지가 길어질 수밖에 없는데요. 여기서 테이블이 하나가 아니라 여러 개가 있다면 그만큼 사용되는 컨텍스트는 더욱 늘어날 수밖에 없기 때문에 주의해야 합니다.
대신 이 경우 Text-Embedding 모델을 함께 사용하면, 컨텍스트가 길어지는 문제를 일부 해결할 수 있습니다. 모든 테이블 스키마 정보를 하나의 프롬프트에 담는 것이 아니라 vector database에 저장해 놓고 Text-Embedding 모델을 통해서 필요한 정보만을 추출해서 프롬프트로 사용할 수 있습니다..
🍀 CLOVA 임베딩 모델 알아보기
CLOVA Studio에서는 아래와 같이 3가지 임베딩 모델을 제공하고 있습니다.
| 도구명 | 모델명 | 최대 토큰 수 | 벡터 차 | 권장 거리 지표 distance metric) | 비고 |
| 임베딩 | clir-emb-dolphin | 500 토큰 | 1024 | IP (Inner/Dot/Scalar Product; 내적) | |
| 임베딩 | clir-sts-dolphin | 500 토큰 | 1024 | Cosine Similarity (코사인 유사도) | |
| 임베딩v2 | bge-m3 | 8,192 토큰 | 1024 | Cosine Similarity (코사인 유사도) | 오픈 소스 모델* |
각 모델들의 특징은 다음과 같습니다.
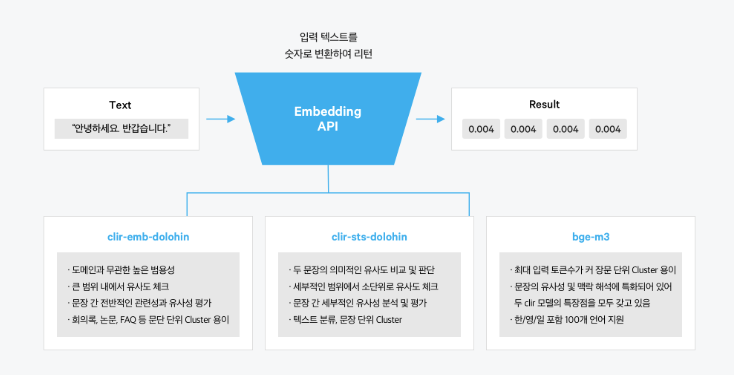
CLOVA Studio에서 제공되고 있는 모델들의 강점이라고 하면 아무래도 국내 모델이기 때문에 한국어에 특화되어 있다는 점일 것 같은데요. 실제로 하이퍼클로바 X Technical Report에 따르면 CLOVA 모델들은 한국어 토크나이저에 강점이 있습니다.

위 표를 토대로 하이퍼클로바 X에 포함된 토크나이저는 적은 토큰으로 효과적인 한국어 생성이 가능하다는 것을 확인할 수 있습니다. 이는 다른 말로, 적은 비용으로 효율적인 한국어를 만들어낸다고 볼 수 있는데요.
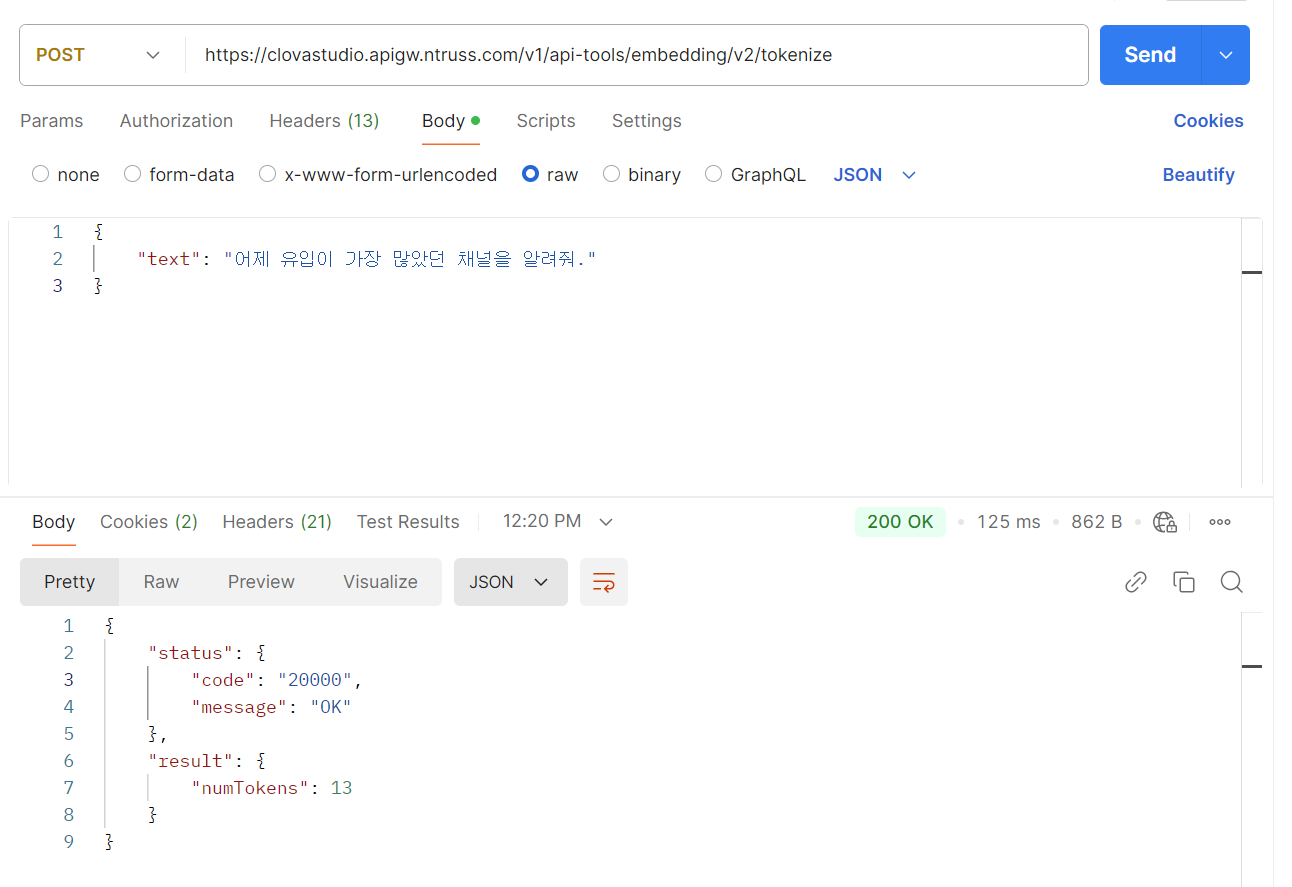
마찬가지로, CLOVA Studio에서 제공되고 있는 Text-Embedding 모델들도 한국어 특화 토크나이저를 사용하고 있기 때문에 비용면에서 이점을 취할 수 있을 것 같습니다. 실제로 CLOVA Studio 익스플로러에서 제공하고 있는 토큰 계산기(임베딩 v2) API를 활용해서 발생한 토큰 수를 계산해 보면 아래 문장에 대해 13 토큰으로 분리가 되었다는 사실을 알 수 있습니다.
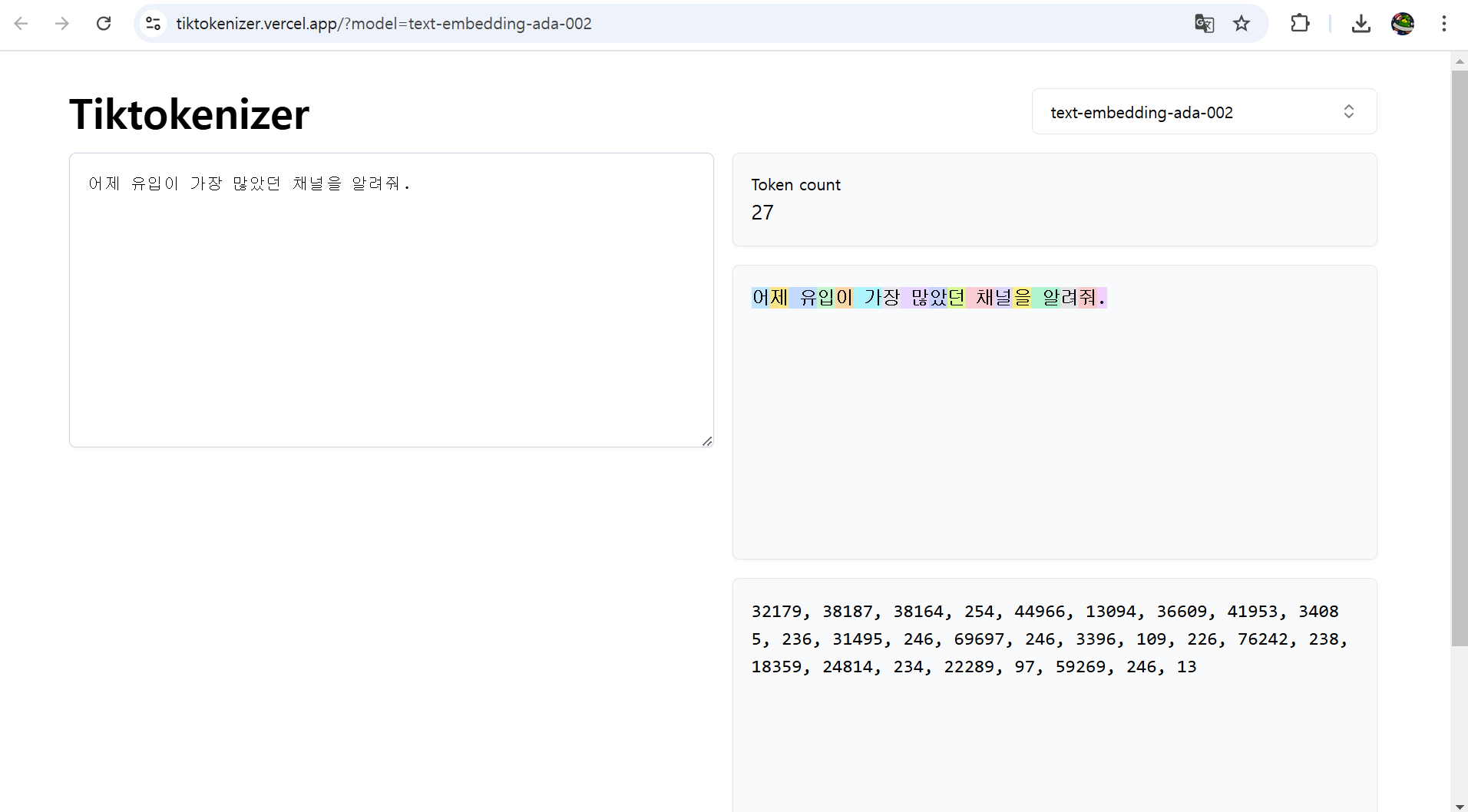
반면, OpenAI에서 제공하고 있는 text-embedding-ada-002 모델은 27 토큰이나 생성해 내는 것으로 보았을 때 확실히 CLOVA 모델들이 한국어 토크나이저 성능면에서는 뛰어나다는 사실을 확인할 수 있습니다.
단, 토크나이저는 CLOVA Studio에서 제공되고 있는 Text-Embedding 모델들 중 임베딩 v2에서만 제공되고 있습니다. 임베딩 v2와 임베딩 v1은 가격 면에서 조금 차이가 있으며 임베딩 v2는 1 토큰당 0.0002원, 임베딩 v1은 1 토큰당 0.0001원으로 계산됩니다.
또한, 임베딩 v2는 한국어 모델 성능이 뛰어나다고 저명한 오픈소스 모델인 bge-m3를 베이스로 사용하고 있습니다. bge-m3에 대한 품질 테스트는 아래 블로그들을 참고하시면 좋을 것 같습니다.
AI 임베딩 모델 한국어 성능 비교
테스트 임베딩 모델아래 임베딩 모델을 테스트했습니다. 상위 3개 모델은 ollama에서 가장 인기 있는 임베딩 모델입니다.nomic-embed-textmxbai-embed-largesnowflake-arctic-embedBAAI/bge-m3테스트 문서아래는 테스
anpigon.tistory.com
한국어 임베딩 모델 성능 비교 테스트 결과 — Steemit
한국어 corpus 데이터셋으로 테스트 했습니다. import autorag from autorag.evaluator import Evaluator from llama_index.embeddings.huggingface import HuggingFaceEmbedding from llama_index.embeddings.openai import OpenAIEmbedding, OpenAIEmbeddin
steemit.com
추가로, CLOVA Studio에서 제공되고 있는 Text-Embedding들에 대한 정보는 아래 네이버클라우드 공식 가이드문서에서 자세히 알아보실 수 있습니다.
https://guide.ncloud-docs.com/docs/clovastudio-explorer03
🚀 In-memory Vector Store 구현하기
랭체인 프레임워크를 사용하고 계시다면 랭체인에는 메모리에 임베딩된 Vector 값을 적재하는 기능을 지원합니다. 따라서, Vector database 없이도 간단한 코드만으로도 손쉽게 구축이 가능합니다. 아래는 예시 코드입니다. (랭체인 v0.3을 기준으로 가이드되고 있는 코드입니다.)
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
vector_store = InMemoryVectorStore(OpenAIEmbeddings())
만약 OpenAIEmbeddings 말고 원하는 임베딩 모델이 있다면 아래와 같이 교체해서 사용이 가능합니다. CLOVA Studio에서 제공하는 임베딩 모델을 사용하는 경우 다음과 같이 변경해서 사용이 가능합니다.
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import ClovaXEmbeddings
vector_store = InMemoryVectorStore(
ClovaXEmbeddings(
model='bge-m3',
api_key=settings.NCP_CLOVASTUDIO_API_KEY,
apigw_api_key=settings.NCP_APIGW_API_KEY,
app_id=settings.NCP_CLOVASTUDIO_APP_ID
)
)
테이블 스키마를 적재할 때는 다음과 같은 코드를 사용할 수 있습니다. 저는 FastAPI가 로드가 처음 로드될 때 한 번만 적재하도록 컨텍스트 매니저에서 라이프사이클 시작 지점에 상태값으로 벡터 스토어 참조값을 저장해 놓았습니다.
# main.py
@asynccontextmanager
async def lifespan(app: FastAPI):
try:
app.state.vector_store = VectorStore(embedding_type=EmbeddingType.CLOVA)
app.state.vector_store.load()
yield
finally:
if hasattr(app.state, "vector_store"):
app.state.vector_store.cleanup()
실제 벡터 스토어에 저장하고 검색하는 로직은 VectorStore라는 클래스를 만들어서 관리할 수 있습니다. (*아래 코드는 예시 코드이므로 실제 구현 부분은 직접 채워주셔야 합니다.)
from langchain.embeddings.base import Embeddings
from langchain_community.embeddings.naver import ClovaXEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.documents import Document
# 초기화
def __init__(self, embedding_type: EmbeddingType = EmbeddingType.CLOVA):
self._store = None
self._embedding_type = embedding_type
# 임베딩 모델 로드
def load(self):
self._store = InMemoryVectorStore(
self._get_embeddings()
)
self._load_schemas()
# vector store에 스키마 적재
def _load_schemas(self):
Document(id="table1_schema", page_content={table1 스키마 정보})
Document(id="table2_schema", page_content={table2 스키마 정보})
schemas = [page_table_schema, landing_page_schema]
self._store.add_documents(documents=schemas)
# vector 검색
def search(self, query: str, k: int = 1):
results = self._store.similarity_search_with_score(query=query, k=k)
filtered_results = [
(doc, score) for doc, score in results
if score > 0.3
]
return filtered_results
Text-to-SQL 기술 구현시 테이블 스키마 정보를 Vector store에 저장할 때는 별도로 chunking(내용을 잘라서 넣는 행위) 과정이 필요 없이 테이블당 한 페이지로 저장하시면 됩니다. 원래 RAG(Retrieval Augmented Generation) 기술을 구현할 때는 문서 내용이 길기 때문에 chunking과정이 필요하지만 테이블 스키마 정보는 그렇게 까지 크지 않기 때문에 chunking을 생략합니다. CLOVA Studio 임베딩 v2 모델은 8192 토큰까지 처리가 가능하므로 넉넉하게 사용할 수 있습니다.
만약 Langserve를 사용하고 계시다면 Route를 추가하실 때 아래와 같이 with_config 함수의 configurable 옵션을 이용하여 app.state에 vector store정보를 전달하시면 랭체인에서 벡터 검색결과를 프롬프트로 사용할 수 있습니다.
add_routes(app, create_classify_table_chain().with_config(
configurable={
"vector_store": lambda: app.state.vector_store
}
), path="/test/table")
랭체인에서는 실제로 다음과 같이 사용할 수 있습니다. (*아래 코드는 예시 코드이므로 실제 구현 부분은 직접 채워주셔야 합니다.)
from langchain.schema.runnable import Runnable, RunnableConfig
from langchain_core.runnables import RunnableLambda
```
from langchain.schema.runnable import Runnable, RunnableConfig
from langchain_core.runnables import RunnableLambda
def create_classify_table_chain() -> Runnable:
"""테이블 분류를 위한 체인 생성"""
def chain_with_schema(input: str, config: RunnableConfig):
vector_store = config["configurable"]["vector_store"]()
results = vector_store.search(query=input, k=4)
return results
chain = (
RunnableLambda(chain_with_schema)
| prompt
| get_llm()
| StrOutputParser()
)
return chain
InMemoryVectorStore 사용하는 방법은 아래 랭체인 공식가이드 문서에서 자세히 확인하실 수 있습니다.
InMemoryVectorStore — 🦜🔗 LangChain documentation
InMemoryVectorStore class langchain_core.vectorstores.in_memory.InMemoryVectorStore(embedding: Embeddings)[source] In-memory vector store implementation. Uses a dictionary, and computes cosine similarity for search using numpy. Setup:Install langchain-core
python.langchain.com
🔐 CLOVA Embedding API키 발급받기
CLOVA Embedding API를 사용하기 위해서는 api_key, apigw_api_key, app_id 3가지 정보가 필요한데요. 이 정보들은 CLOVA Studio 익스플로러 메뉴의 임베딩 v2 도구에서 확인하실 수 있습니다.
CLOVA Studio
clovastudio.ncloud.com
임베딩 v2메뉴에 접속하셔서 아래와 같이 테스트 앱 생성 버튼을 통해 테스트 앱을 생성합니다.

테스트 앱을 생성하고 난 후에는 다음과 같이 필요한 정보들을 확인하실 수 있습니다.

CLOVA Text-Embedding 모델 사용방법에 대한 가이드는 네이버클라우드 포럼에 cookbook으로 많이 등록되어 있기 때문에 쉽게 정보를 찾아보실 수 있습니다.
🦜🔗 랭체인(Langchain)으로 Naive RAG 구현하기 cookbook
본 가이드는 클로바 스튜디오(CLOVA Studio)와 랭체인(Langchain)을 이용해 RAG(Retrieval Augmented Generation; 검색 증강 생성) 시스템을 만드는 방법을 설명합니다. NCP 가이드: https://guide.ncloud-docs.com/docs/clovast
www.ncloud-forums.com
Advanced RAG 구현을 위한 🦜🔗 랭체인 cookbook
본 Cookbook은 기존 🦜🔗 랭체인(Langchain)으로 Naive RAG 구현하기 cookbook에서 한 단계 더 나아가, 다양한 CLOVA Studio API와 오픈소스 도구들을 활용해 고급 검색 및 생성 기능을 구현하는 방법을 소개합
www.ncloud-forums.com
🌠 정리하기
지금까지 CLOVA Studio의 Text-embedding 모델을 활용해 Text-to-SQL을 위한 랭체인 Vector DBLess 환경 구현 방법에 대해 알아보았는데요. 실제로 위 환경을 토대로 In memory Vector Store에 테이블 스키마 정보를 임베딩하여 저장해 놓고 검색했을 때 사용자 질문에 대한 검색 결과를 어떤 테이블에서 찾아내야 하는지 생각보다 잘 찾아내는 것을 확인할 수 있었습니다.
특히, 저의 경우에는 컬럼들이 15개씩 존재하는 4개의 테이블 스키마 정보를 적재하였는데 인메모리 방식을 사용할 때 우려되었던 로딩속도나 성능면에서도 크게 문제가 발현되지 않았습니다. 다만, 동시 사용자 수가 많아짐에 따라서 메모리 접근량이 많아져서 문제가 발생할 수는 있을것 같습니다.
따라서 Text-to-SQL 구현시 가볍게 테스트 해보고싶을때 이런 In memory Vector Store방식으로 기술을 검토해보셔도 좋을것 같다는 생각이 듭니다. 또한, 사용자들을 국내로 타겟팅 하고 있다면 CLOVA Studio에서 제공하고 있는 Text-embedding 모델을 활용해 높은 한국어 이해를 바탕으로 정확한 테이블을 찾아내는 경험을 해보는것도 추천드립니다.